1、一些电子版的书籍大多通过扫描的方式得到,这类的PDF称为扫描版的PDF。好的,我们就来处理这类文档吧

2、以上面上传的PDF截图为例,把它当做是扫描版的PDF文档的部分页面。首先大家通过页面直观的就可以看出它是扫描版的文档:点击文本,文本选中,无法复制
右击没有复制命令
点击页面变色
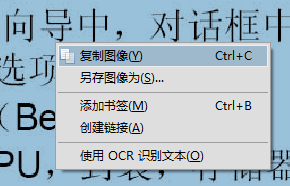

3、好的,然后我们可以开始识别工作了。一次点击{文档}{OCR文本识别}{使用OCR识别文本}
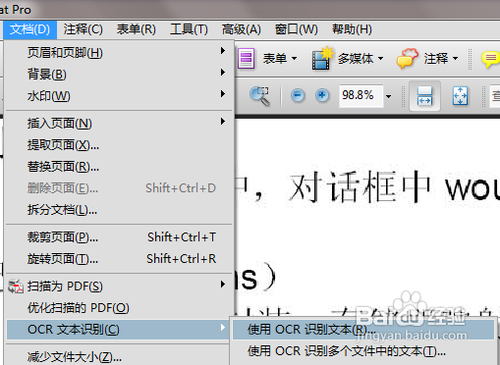
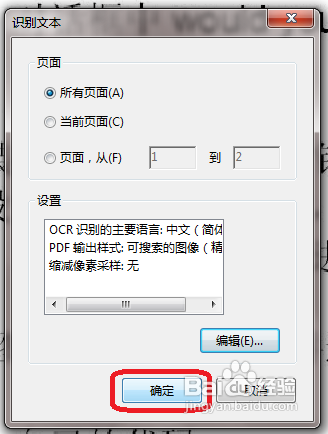
4、在弹出窗口根据需要选择{所有页面}或者{当前页面}
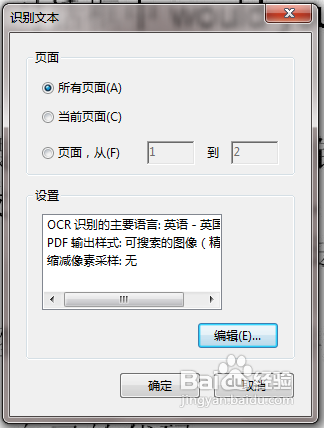
5、点击编辑设置需要识别的语言。如果是中文简体,就选择它,如果是英语就选择英语
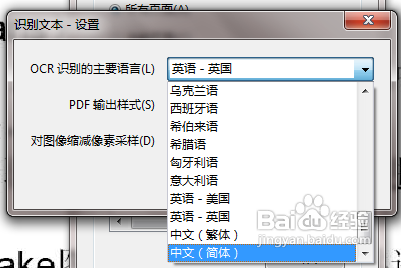
6、点击确定,开始识别
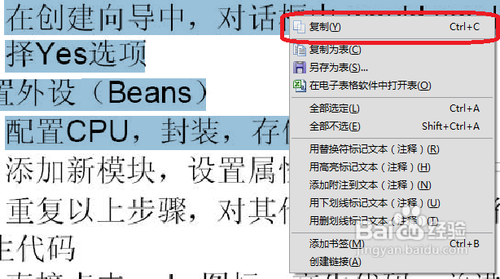
7、通过几秒钟的识别处理,我们发现原来不能复制的文档内容可以右击复制~\(≧▽≦)/~啦啦啦
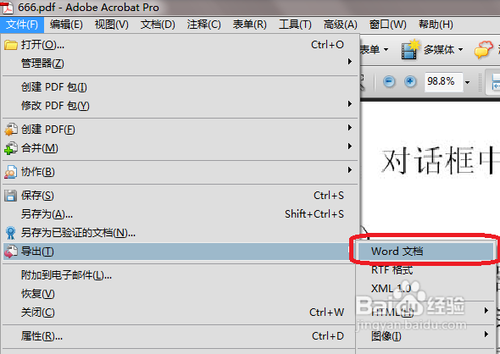
8、最后我们一次点击{文件}{导出}{word文档}可以将其导出为文档,开始编辑了。完美!!
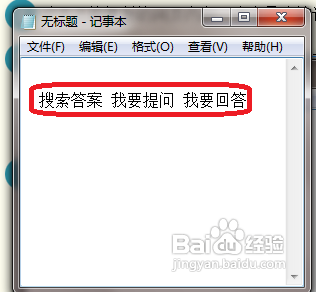
1、对于不能复制的网页内容,这个是比较讨厌的,就来对付他们吧
2、以取材以大家熟悉的内容为原则,我们来处理一下百度知道的三个按钮吧,哈哈。

3、首先,利用截屏按钮或者截图软件把需要识别的部分截图成图片。利用系统自带画图软件,得到需要处理的部分图片
4、把图片保存在桌面或者其它你容易找到的位置。右击转化为PDF文档
5、然后按照{识别扫描版的PDF文档}的相应步骤我们就可以得到下面内容啦